Armar un Datacenter. Tuqui.
Una cosa que quise hacer desde siempre. ¿Desde cuándo siempre? Desde mi tierna adolescencia: cuando comprendí que un par de compus en red podían sentar las bases infraestructurales para levantar servicios "de la interwebz". Lo interesante, es que en todas las iteraciones que lo intenté, a lo largo de todos estos años, siempre me faltó algo, mayormente tiempo y dinero. Usé computadoras variopintas para estos proyectos pero siempre terminaba todo en la nada ya sea por falta de hardware, conocimiento, tiempo o por pura paja.
También estoy escribiendo este artículo hace demasiado y en algún momento
tengo que frenar. Lo último que estaba haciendo antes de cortar este
artículo era configurar todo un entorno de desarrollo y deployment
con Flux. Está muy bien, pero después de Flux: ¿Qué sigue?
Y… todo sigue. Esta profesión tiene la particularidad que pareciera
ser infinita y nunca terminara.
En algún momento del año pasado, se estaba cristalizando la idea de armar un pequeño datacenter (o HomeLab) para mi. En Hetzner, tenía varios servicios funcionando para mis cosas, pero algunas de estas aplicaciones requerían mucha capacidad de almacenamiento y estaba volviéndose muy caro mantener todo esto en "la nube".
A mitad del año pasado, reduzco la cantidad de servidores al mínimo: paso de 7 servidores para mis servicios a solamente 2, con moderado éxito. Tengo que remover y hacer backups de las aplicaciones que uso que requieren mucho almacenamiento y ponerlas offline para reducir costos.
Por otro lado, consigo un NAS Synology DS923+ con varios discos y es suficiente para almacenar muchas de mis otras cosas, pero en algún momento, necesito volver a tener mis servicios andando nuevamente y el almacenamiento ya no es un problema.
Entonces con el aguinaldo en mano, hago unos presupuestos e investigo que opciones hay en mercados de usados/refurbished para conseguir algunas computadoras, placas, cables, Switches y abandonar "la nube" completamente.
Antes de empezar, debo decir que hay una tendencia en la industria del software que está empezando a considerar cada vez más fuertemente alejarse de las soluciones corporativas de "la nube" y hostear el software on-premise. Todavía no entiendo bien si esta tendencia está dada para abaratar costos en el largo plazo o simplemente porque armar soluciones en la nube, hoy, es mucho más sencillo.
Y antaño es hace, no sé, ¿Dos, tres años? ;D
El Hardware
Empecemos por listar el hardware mínimo para correr mi Datacenter:
- Synology DS923+, 4 Bay, 2 HDD 8TB y 2 HDD 16TB en SHR1. Todos los discos de tipo NAS menos uno que es un EXOS y que por ahora no esta integrado al volumen y lo tengo como hotspare. Capacidad total 14 TB. La configuración no es óptima asi como tampoco el precio de estos discos.
- Cuatro Lenovo ThinkCentre (m720q y m920q) Tiny, ~i5-9500T, 16/32 GB, 240 GB SSD
- Placa de red Intel i350-T4 4 port gigabit PCIe
- 01AJ940 Raiser Para Lenovo Thinkcentre M920x
- TP-Link Archer AX55 Wi-Fi 6 WLAN Router, 2402 Mbps 5 GHz, 574 Mbps 2.4 GHz, 4 × Gigabit LAN Ports, 1 × USB 3.0 Port
- TP-Link TL-SG116E 16-Port Gigabit Switch
- Cables Cat 5.e ó mejores
- Netgear GS108E Managed Switch 8 Port Gigabit Ethernet LAN Switch Plus
Muchos de estos componentes son relativamente baratos. Los más baratos son los switches, los cables y el router wifi. Los más caros, son las computadoras y la placa de red Intel, que es usada para servidores. Lo interesante de esto, es que todos los componentes caros son usados y refurbisheados, lo que los hacen increiblemente accessibles, sin contar que estamos dándole vida a cosas que tiraron prácticamente a la basura previamente. En el país en el que vivo, hay empresas que se dedican a restaurar y arreglar hardware viejo y roto para la reventa a precios ridículos.
Los switches parecen una exageración, pero tengo muchos dispositivos conectados a una red una Pentium MMX, una Commodore 64 con WIC64 y otras cosas divertidas las cuales escriba quisá en algún otro post.
 Desarmando dos ThinkCentres y preparando la instalación de una placa
Desarmando dos ThinkCentres y preparando la instalación de una placa
Lo interesante de estas máquinas Lenovo ThinkCentre M920q Tiny, es que son muy pequeñas, y el consumo en IDLE ronda alrededor de 10W asi que la factura de luz no se incrementa demasiado según mis cálculos y sigue siendo una opción más barata que rentar máquinas virtuales en cualquier proveedor de "la nube". También es interesante que estas máquinas, particularmente soportan IOMMU y SR-IOV para poder hacer PCIe Passthrough, que es precisamente algo importantísimo en mi setup, ya que necesito armar un firewall y un router para mi datacenter. Y es acá donde entra en acción la interacción entre las ThinkCentre y la placa de red Intel i350T4.
 La placa de red que va a tener una de las ThinkCentre
La placa de red que va a tener una de las ThinkCentre
El primer problema de todos, es como metemos esta placa en una máquina con espacio tan reducido y además, con un slot PCIe que tiene una orientación que simplemente no permite la instalación de ninguna placa.
 Oops! La placa de red no entra ni a palos acá en el único slot PCIe
Oops! La placa de red no entra ni a palos acá en el único slot PCIe
Ahi es donde viene una parte que solo pude conseguir en China, que es
el Riser 01AJ940, específicamente diseñado para cambiar la dirección vertical del slot
a una horizontal.
 Riser 01AJ940 conectado a una de las ThinkCentre. Se puede ver como cambia la dirección del slot
Riser 01AJ940 conectado a una de las ThinkCentre. Se puede ver como cambia la dirección del slot
Esta parte, debería haber venido con un adaptador para la parte del chasis de la ThinkCentre que lo que hace es sostener la placa en el aire para que los contactos de la parte trasera de la placa no toquen ningún componente del motherboard ó el chasis. Y no, solo me vino el Riser sin el adapador, asi que tuve que atarlo con alambre.
 Cortamos unos pedazos de cartón…
Cortamos unos pedazos de cartón…
 … y se lo chantamos ahi masomeno’
… y se lo chantamos ahi masomeno’
 No cierra bien el chasis de este servidor, y quedaron unos huecos a los costados de la placa, pero bueno :D
No cierra bien el chasis de este servidor, y quedaron unos huecos a los costados de la placa, pero bueno :D
Con esta máquina ensamblada de nuevo, ya podemos empezar a armar en uno de nuestros nodos del Datacenter, un router/firewall con pfSense, virtualizado obvio, pero permitiéndole a la VM capturar el hardware directamente vía PCIe Passthrough.
Es importante destacar que la elección de todo este hardware estuvo directamente basada en las funcionalidades descriptas para poder permitir que las VMs puedan usar la placa de red directamente, sin que el sistema operativo del Host estuviera involucrado.
Interesantemente, antes de comprar este hardware estuve jugando muchísimo con
libvirt pensando inocentemente que podría emular todo el datacenter en mi
PC de escritorio. En teoría es posible, pero el hardware de mi PC de escritorio
es muy malo y no solo no me permite capturar componentes conectados en los slots PCIe,
sino que también mi placa de red Realtek es una reverenda mierda.
Pude hacer andar todo, si, pero sin buen hardware, las redes virtualizadas en placas
de mierda, son tremendamente inestables.
Solo cuando me dí cuenta de esto, entendí que debía comprar hardware de todas maneras. Además, inutilizar mi PC para correr un cluster, tampoco era una opción.
Proxmox
 Instalando Proxmox
Instalando Proxmox
Habiendo ganado mucha experiencia (y peleas) con libvirt tuve que tomar una decisión. ¿Uso libvirt o cambio a Proxmox?
Por detalles en los que no voy a ahondar, prácticamente Proxmox fue la decisión correcta. Integra el Hypervisor KVM, soporta Linux Containers (LXC) out-of-the-box y también funciona como cluster. Cada instalación de Proxmox puede funcionar como un nodo único o podés incluir el nodo en un cluster para organizar y distribuir el uso de recursos de containers o VMs.
Toda la explicación del hardware en este artículo converge exactamente en este mapeo de recursos. La VM "pfSense" tiene estos recursos asignados:
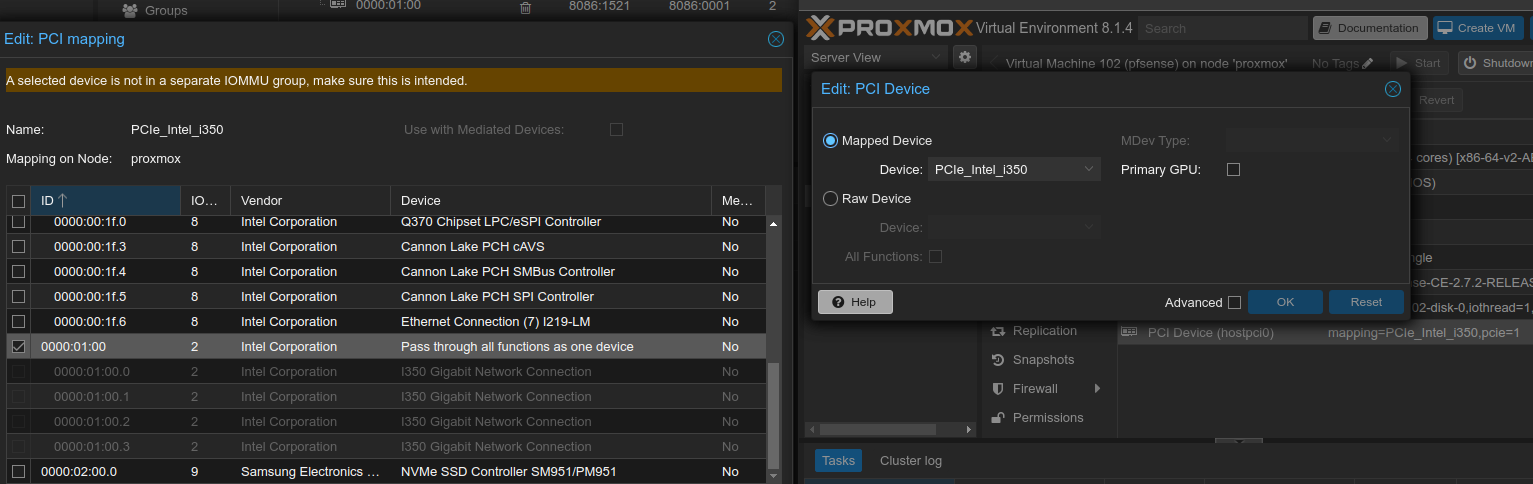 Proxmox Intel i350-IOMMU - Dispositivo Mappeado a esta VM con PCI Passthrough
Proxmox Intel i350-IOMMU - Dispositivo Mappeado a esta VM con PCI Passthrough
Ahora, al instalar pfSense en una VM hosteada por Proxmox,pfSense detecta
los cuatro puertos ethernet como si fueran propios, interactuando directamente
con el hardware, sin intermediarios.
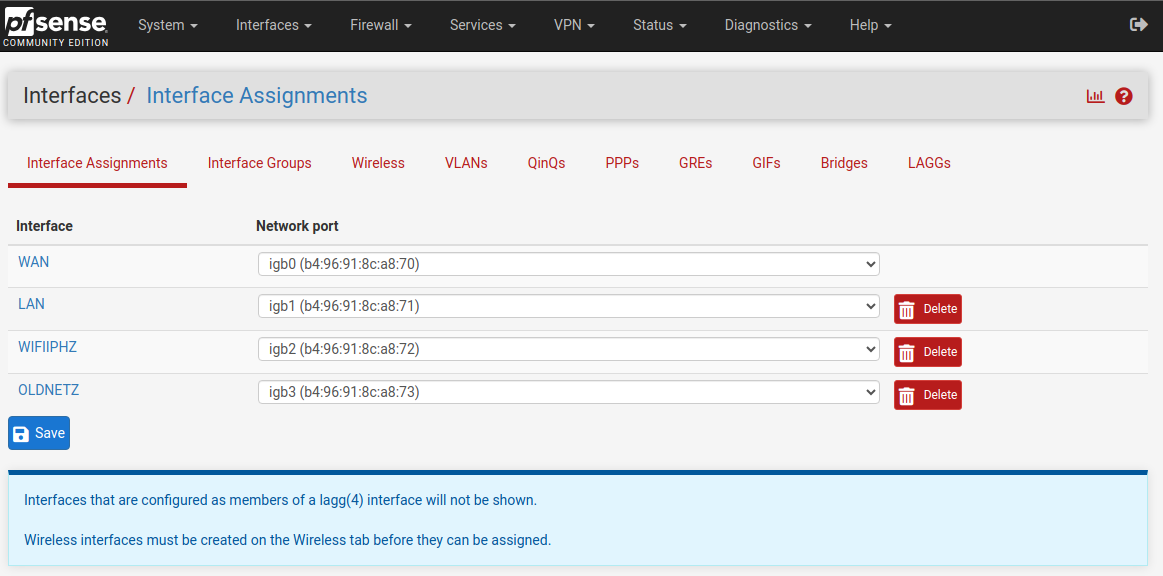 Interfases detectadas por pfSense via a Proxmox VM con PCI Passthrough
Interfases detectadas por pfSense via a Proxmox VM con PCI Passthrough
En este punto, ya tenemos un router andando. Como configurar un router/firewall como pfSense amerita un artículo completamente distinto y mi setup es más complejo que
lo que quiero explicar en este.
Pero brevemente, tengo 4 interfaces, de los cuales salen 4 cables a el switch
de 16 puertos, segmentado o aislados por VLANs para separar las compus viejas, el wifi, la tele y varios dispositivos electrónicos, asi como también no permitir
el acceso a mi red a invitados.
¿Porqué? Porque tengo conectado un Windows 3.11 en mi red con File Sharing a un Windows 10,
una máquina MS-DOS también con Packet Driver y una 3COM y cualquiera que tuviera
una PC conectada a mi red, podría hacer desmanes.
Sin contar que la Commodore 64 también está conectada a la red y a la internet.
Mismo procedimiento luego para incluir la otra ThinkCentre en el cluster Proxmox, joinearlo como nodo y conectando un drive NFS para tener almacenamiento suficiente para las VMs.
Y ahi arrancó un nuevo problema.
Demasiado Acceso a Disco
Resulta que cuando empecé a conectar VMs al drive NFS del NAS, los discos empezaron a hacer ruido, y fuerte. Aunque tenga redundancia en los discos a través de SHR, tampoco es que por solamente tenerlo encendido para que las VMs estén disponibles, vayan desgastándolos lentamente acortando su vida útil, eventualmente fallando uno (o varios) de ellos, y tener que reemplazar el disco roto. Y los discos no son algo necesariamente barato. Asi que me puse a ver como hacer para minimizar la escritura a disco de las VMs de Linux que tenia corriendo.
Las distribuciones de Linux, o al menos las más comunes o importantes, tienen settings por default que necesitamos cambiar.
Habiendo cambiado algunas propiedades en el fstab y midiendo el las escrituras
y lecturas pude minimizar las escrituras. Pero configurar VM por VM cuando tenés
más de diez corriendo, es totalmente impracticable. Especialmente si por cada nueva
instalación de una VM, tenés que pasar por los mismos tweaks una y otra vez.
Entonces, a la 3er VM que estaba configurando, pensé en armar un template "base" con todas las cosas configuradas y chantársela a las nuevas VMs en el momento de la creación. Asi, solo configuro una imagen con todos mis settings óptimos y me olvido de cualquier configuración adicional.
Con Packer de Hashicorp, preparar imágenes para VMs es "relativamente" sencillo.
Packer y cloud-init, un solo corazón
Con Packer lo que vamos a hacer es crear una imagen exclusiva para mi cluster (o el tuyo), para que cada nueva VM tenga todo configurado, ahorrándonos un montón de tiempo.
Cuando dije anteriormente que Packer es "relativamente" sencillo, es en principio
verdad. Definís una VM para buildear la imágen, conectas un ISO con cloud-init
y le decís a la imagen como construirse con subiquity si usas Ubuntu Server o cualquier Debian based Distro.
El tema escomo los layers de abstracción; el orden de ejecución de autoinstall
de Ubuntu Server subiquity; y finalmente en que momento diferentes instancias de cloud-init son ejecutadas
es increíblemente confuso.
cloud-init se ejecuta en varias instancias dependiendo de el contexto de ejecución:
- La instancia de la creación de la imagen.
- La instancia del uso de esta imagen en la creación de la VM.
La documentación tampoco ayuda mucho y ni que hablar de las diferencias entre versiones. La parte menos importante de todo esto es el archivo de Packer en si. Asi que lo pasamos rápido, mostrando las partes más importantes:
packer {
required_plugins {
name = {
version = "~> 1"
source = "github.com/hashicorp/proxmox"
}
}
}
source "proxmox-iso" "proxmox-ubuntu-server-jammy" {
proxmox_url = var.proxmox_api_url
username = var.proxmox_api_token_id
token = var.proxmox_api_token_secret
node = "px-03"
vm_id = "9666"
vm_name = "packer-proxmox-ubuntu-server-jammy-1"
iso_url = "https://old-releases.ubuntu.com/releases/jammy/ubuntu-22.04.4-live-server-amd64.iso"
# get the checksum from https://releases.ubuntu.com/22.04/SHA256SUMS
iso_checksum= "45f873de9f8cb637345d6e66a583762730bbea30277ef7b32c9c3bd6700a32b2"
iso_storage_pool = var.proxmox_storage_pool
ssh_username = "ubuntu"
ssh_password = "ubuntu"
ssh_timeout = "10m"
cloud_init = false
cloud_init_storage_pool = var.proxmox_storage_pool
[...]
template_name = "packer-ubuntu-server-jammy"
template_description = "Packer generated Ubuntu 22.04"
unmount_iso = true
additional_iso_files {
cd_files = [
"./http/meta-data",
"./http/user-data",
]
cd_label = "cidata"
unmount = true
iso_storage_pool = var.proxmox_storage_pool
}
memory = "4096"
cores = "4"
sockets = "1"
os = "l26"
machine = "q35"
qemu_agent = true
scsi_controller = "virtio-scsi-pci"
disks {
disk_size = "8G"
# qcow2 over raw, because NFS in my system
# but it's not supported by terraform proxmox (???)
# update: months after, it's supported. Todo piola!
# https://forum.proxmox.com/threads/raw-vs-qcow2.34566/
format = "qcow2"
storage_pool = var.proxmox_disks_nas_storage_pool #Specify your storage pool
#storage_pool_type = "zfs" #Specify pool type
type = "virtio"
# writeback increase of r/w speed
# https://forum.proxmox.com/threads/virtio-vs-scsi.52893/
cache_mode = "writeback"
}
[...]
}
# Build Definition to create the VM Template
build {
name = "proxmox-ubuntu-server-jammy"
sources = ["source.proxmox-iso.proxmox-ubuntu-server-jammy"]
# Provisioning the VM Template for Cloud-Init Integration in Proxmox #1
provisioner "shell" {
inline = [
"while [ ! -f /var/lib/cloud/instance/boot-finished ]; do echo 'Waiting for cloud-init...'; sleep 1; done",
"sudo rm /etc/ssh/ssh_host_*",
"sudo truncate -s 0 /etc/machine-id",
"sudo apt -y autoremove --purge",
"sudo apt -y clean",
"sudo apt -y autoclean",
"sudo cloud-init clean",
"sudo rm -f /etc/cloud/cloud.cfg.d/subiquity-disable-cloudinit-networking.cfg",
"sudo sync"
]
}
[...]
}
Filesystem Mount Options
Una de las cosas que queremos hacer para minimizar el acceso da disco,
es que en momento de provisionar la imagen o el template que estamos armando
con packer, se hacen configuraciones de algunos flags de varios componentes
del sistema operativo. Como por ejemplo, en el fstab generalmente
tenemos algunas líneas como la siguiente:
UUID=b22312e6-a495-4a5b-959f-4d73ec97e9bf / ext4 errors=remount-ro 0 1
Como default, esta bien, pero nosotros necesitamos para nuestro escenario
particular, donde queremos minimizar las escrituras a disco, un fstab que
se vea más o menos así:
UUID=b22312e6-a495-4a5b-959f-4d73ec97e9bf / ext4 discard,noatime,nodiratime,errors=remount-ro 0 1
Donde:
discard- le dice al device que descarteblocks. Si el dispositivo no lo soporta, no tiene efectonoatime- no guardes información sobre el tiempo de acceso a archivosnoadate- no guardes información sobre la fecha de acceso a archivosnodiratime- no guardes el tiempo de acceso a directorios
Reconfigurar journald
El journald en su configuración por defecto escribe una banda a disco, guardando
todos los logs posibles.
En años de experiencia, debo decir también que esta es solo mi opinión,
que hay dos instancias donde se revisan los logs. La primera es
cuando por colectarlos y procesarlos, salta alguna alerta
para revisar. La segunda, es cuando ya es demasiado tarde.
Si algún proceso no está funcionando más, esa instancia
de logs de systemd/journald va a dejar de producir logs.
Entonces es innecesario estar guardando logs sobre el estado
de cada una de las aplicaciones a disco si son consumidos
desde otros procesadores de logs. Por eso, desactivamos
y configuramos algunas cosas de journald para que los
logs queden en memoria. Para esto, en nuestro packer
debemos lograr escribir /etc/systemd/journald.conf.d/50-local.conf con la siguiente configuración:
[Journal]
Storage=volatile
RuntimeMaxUse=128M
ForwardToSyslog=no
sysctl swappiness a 1
Hay un parámetro del Kernel de Linux que controla el swapping
de la información de una aplicación (como páginas anónimas)
de la memoria física a la memoria virtual al disco.
Se llama vm.swappiness. Este parámetro va de 0 a 100.
Mientras más alto este parámetro, más posibilidades hay que procesos inactivos swappeen fuera de la memoria física; mientras más bajo el valor, se swappea menos, forzando los bufferes del filesystem que se vacíen.
Entonces, bajemos la probabilidad al mínimo seteando este valor a 1 para minimizar la escritura a disco de la siguiente manera:
echo "vm.swappiness = 1" >> /target/etc/sysctl.conf
Clavándola con autoinstall, user-data y Packer
Todas estas configuraciones están barbaras, pero las tenemos
que cristalizar en un template de proxmox para que cuando
empecemos a crear VMs con terraform, no solo algunos
packetes esten en el template/imagen preconfiguradas,
pero también algunos settings en el sistema operativo.
Recordemos, esta configuración es para mi cluster. Cada datacenter, arquitectura, cableado, discos, servidores tendrá sus propias particularidades. En mi caso, escritura a disco era un problema. Entonces, ¿Cómo armamos esa imagen para nuestro "cluster super ecológico" ? ¿Cómo lo automatizamos?
En nuestro archivo pkr donde definimos nuestra imagen,
tenemos una sección donde podemos definir user-data donde
declaramos los pasos que autoinstall va a ejecutar en la
creación del template:
source "proxmox-iso" "proxmox-ubuntu-server-jammy" {
[...]
additional_iso_files {
cd_files = [
"./http/meta-data",
"./http/user-data",
]
cd_label = "cidata"
unmount = true
iso_storage_pool = var.proxmox_storage_pool
}
[...]
}
Las secciones relevantes de nuestro archivo user-data
son las siguientes:
#cloud-config
# autoinstall reference
# https://canonical-subiquity.readthedocs-hosted.com/en/latest/reference/autoinstall-reference.html#user-data
autoinstall:
autoinstall:
version: 1
locale: en_US
keyboard:
layout: es
[...]
storage:
#layout:
# name: direct
config:
- id: disk0
type: disk
wipe: superblock-recursive
ptable: msdos
model: QEMU HARDDISK
path: /dev/vda
name: system-disk
preserve: false
grub_device: true
- id: disk0-part1
device: disk0
type: partition
#partition_type: EF02
name: boot-partition
number: 1
#size: 512MB
size: 1GB
flag: boot
preserve: false
- id: disk0-part2
device: disk0
type: partition
preserve: false
size: 4GB
resize: true
name: root-partition
number: 2
#wipe: superblock
- id: disk0-part1-format-boot
type: format
volume: disk0-part1
fstype: ext4
label: boot
- id: disk0-part2-format-root
volume: disk0-part2
type: format
fstype: ext4
label: root
- id: disk0-part1-mount-boot
type: mount
path: /boot
device: disk0-part1-format-boot
options: 'discard,noatime,nodiratime,errors=remount-ro'
- id: disk0-part1-mount-root
type: mount
path: /
device: disk0-part2-format-root
options: 'discard,noatime,nodiratime,errors=remount-ro'
swap:
size: 0
late-commands:
- |
rm /target/etc/netplan/00-installer-config.yaml
cat <<EOF > /target/etc/netplan/80-my-net.yaml
network:
version: 2
#renderer: networkd
ethernets:
enp18:
match:
name: enp*
set-name: eth0
dhcp4: true
EOF
# configure journald to minimize disk writes
- |
mkdir /target/etc/systemd/journald.conf.d
cat <<EOF > /target/etc/systemd/journald.conf.d/50-local.conf
[Journal]
Storage=volatile
RuntimeMaxUse=128M
ForwardToSyslog=no
EOF
- echo "vm.swappiness = 1" >> /target/etc/sysctl.conf
user-data:
package_upgrade: false
hostname: packerimage
manage_etc_hosts: true
timezone: Europe/Vienna
users:
- name: ubuntu
groups: [adm, sudo]
lock-passwd: false
sudo: ALL=(ALL) NOPASSWD:ALL
shell: /bin/bash
passwd: "$6$exDY1mhS4KUYCE/2$zmn9ToZwTKLhCw.b4/b.ZRTIZM30JZ4QrOQ2aOXJ8yk96xpcCof0kxKwuX1kqLG/ygbJ1f8wxED22bTL4F46P0" #ubuntu
En el id disk0-part1-mount-root y el id disk0-part1-mount-boot
declaramos las opciones de montaje de la unidad como habíamos mencionado en la sección anterior de este artículo:
options: 'discard,noatime,nodiratime,errors=remount-ro'
swap:
size: 0
De yapa, también decimos en la sección storage: que no vamos
a tener swap.
late-commands:
- |
rm /target/etc/netplan/00-installer-config.yaml
cat <<EOF > /target/etc/netplan/80-my-net.yaml
network:
version: 2
#renderer: networkd
ethernets:
enp18:
match:
name: enp*
set-name: eth0
dhcp4: true
EOF
# configure journald to minimize disk writes
- |
mkdir /target/etc/systemd/journald.conf.d
cat <<EOF > /target/etc/systemd/journald.conf.d/50-local.conf
[Journal]
Storage=volatile
RuntimeMaxUse=128M
ForwardToSyslog=no
EOF
- echo "vm.swappiness = 1" >> /target/etc/sysctl.conf
Luego, además de cambiar el nombre de las interfaces de red
de la que se usa en ubuntu (enp*) a la vieja y querida
definición eth0.
Lo que sigue luego es sencillo, configuramos journald
con los settings que discutimos anteriormente y seteamos a 1
el swappiness en /etc/sysctl.conf. Es importante saber,
que en esta fase de configuración, el disco donde se está
instalando el sistema operativo esta montado en el mountpoint
"/target"
Una ves que tenemos todas nuestras definiciones armadas, ejecutamos:
$ packer build -force -var-file=vars.pkrvars.hcl .
Luego que termine de ejecutar, un template va a estar disponible
en nuestro nodo proxmox para poder referenciarlo en terraform
y usarlo como template base para instalar nuestra propia
imagen Linux en cada nueva Virtual Machine.
Terraform con Proxmox
Primero lo primero. Definir nuestros providers:
terraform {
required_version = ">= 1.7.0"
required_providers {
proxmox = {
source = "bpg/proxmox"
version = "0.66.2"
}
ssh = {
source = "loafoe/ssh"
version = "2.7.0"
}
tls = {
source = "hashicorp/tls"
version = ">= 4.0"
}
}
}
provider "proxmox" {
endpoint = var.proxmox_api_url
username = "root@pam" # for SSH
password = var.proxmox_ssh_password # SSH password
insecure = true
ssh {
agent = true
}
}
Tener en cuenta que este ambiente no es apto para un ambiente de producción. En caso de querer autenticarnos con proxmox a través de terraform, debemos crear una API Key de manera segura con la lista de permisos permitidos y mínimos para que terraform pueda interactuar con el Proxmox cluster.
Después de configurar API Keys, usuarios, SSH y accesos de Proxmox
para el provider de Terraform en mi máquina local
y ya teniendo la imagen construida con Packer podemos
empezar a levantar con nuestros scripts de Terraform, un pequeño
cluster Kubernetes, como ejemplo.
Voy a crear con las siguientes definiciones dos VMs.
Una con un controlplane y la otra con un agent
de la siguiente manera:
variable k3s_control_plane_instances {
description = "Proxmox/k3s number of control planes for this cluster"
type = number
default = 1
}
variable k3s_agent_instances {
description = "Proxmox/k3s number of agents for this cluster"
type = number
default = 1
}
Como ejemplo para levantar un Kubernetes Control-Plane y un Kubernetes Agent.
Todo parece muy complicado, pero escencialmente es armar unas VMs
comunes y corrientes y correrles un cloudinit dependiendo
si son control planes o agents.
Lo que si, hay un detalle.
Para poder controlar todo el cluster Kubernetes es importante
poder recuperar su archivo kubeconfig.
Con todo esto dicho, la configuración del primer control-plane:
resource "proxmox_virtual_environment_file" "k3s_control_plane_cloudinit" {
count = var.k3s_control_plane_instances
node_name = var.proxmox_main_node_name
content_type = "snippets"
# it is needed to add a "snippet" storage in proxmox node
# at Datacenter>Storage section
datastore_id = "terraform_snippets"
[...]
source_raw {
data = <<EOF
[...]
write_files:
- path: /root/control-plane-setup.sh
permissions: 0744
content: |
#!/bin/bash
if [[ `hostname` == "k3s-control-plane-0" ]]; then
echo "curl -fL https://get.k3s.io | sh -s - server --cluster-init --token \"secret\" --write-kubeconfig-mode \"0644\" --disable traefik --disable servicelb --bind-address \`hostname -i\` --tls-san \"k3s-control-plane-${count.index}.tsh\" "
else
echo "curl -fL https://get.k3s.io | sh -s - server --token \"secret\" --write-kubeconfig-mode \"0644\" --disable traefik --disable servicelb --bind-address \`hostname -i\` --server https://k3s-control-plane-0.tsh:6443 --tls-san \"k3s-control-plane-${count.index}.tsh\" "
fi
[...]
EOF
file_name = "k3s-control-plane-${count.index}-cloud-config.yaml"
}
}
Que lindo tener mi propio TLD (top level domain) llamado .tsh <3
Todo esto viene de un previamente configurado pfSense.
Como se construye toda la parte de red amerita otro artículo.
IMPORTANTE: nótese el --token \"secret\". El token del cluster, no está generado. Esta hardcodeado como secret.
Guarda con eso, ¿Eh?. Está mal y el token tiene que ser generado, secreto y fuera de cualquier repositorio
y del alcance de los niños.
Cotinuamos con nuestra definición de Virtual Machine para el control-plane:
resource "proxmox_virtual_environment_vm" "k3s_control_plane" {
count = var.k3s_control_plane_instances
node_name = var.proxmox_main_node_name
vm_id = "505${count.index}"
name = "${var.k3s_hostname_prefix}-control-plane-${count.index}"
description = "k3s cluster managed by Terraform"
tags = ["terraform", "k3s", "control-plane"]
agent {
enabled = true
}
machine = "q35"
cpu {
architecture = "x86_64"
cores = 2
sockets = 1
type = "x86-64-v2-AES"
}
memory {
dedicated = 2048
floating = 2048 // set equal to dedicated to enable ballooning
}
initialization {
ip_config {
ipv4 {
address = "dhcp"
}
}
user_data_file_id = element(proxmox_virtual_environment_file.k3s_control_plane_cloudinit.*.id, count.index)
}
// fake mac-addr for pfSense identification
network_device {
bridge = "vmbr0"
mac_address = "ee:ee:ee:00:00:1${count.index}"
}
operating_system {
type = "l26"
}
vga {
memory = 16
type = "std"
}
//serial_device {}
clone {
vm_id = 9666
node_name = var.proxmox_main_node_name
datastore_id = var.proxmox_disks_nas_storage_pool
}
}
output "control_plane_hostnames" {
description = "Control Planes Hostnames"
value = proxmox_virtual_environment_vm.k3s_control_plane.*.name
}
resource "terraform_data" "clean_ssh_known_hosts" {
count = length(proxmox_virtual_environment_vm.k3s_control_plane) != 0 ? 1 : 0
depends_on = [ proxmox_virtual_environment_vm.k3s_control_plane ]
# clean up the first control plane local ssh known_hosts
provisioner "local-exec" {
command = "ssh-keygen -f \"/home/$USER/.ssh/known_hosts\" -R \"${proxmox_virtual_environment_vm.k3s_control_plane.0.name}.tsh\""
}
}
resource "ssh_sensitive_resource" "grab_kubeconfig" {
count = length(proxmox_virtual_environment_vm.k3s_control_plane) != 0 ? 1 : 0
# The default behaviour is to run file blocks and commands at create time
# You can also specify 'destroy' to run the commands at destroy time
when = "create"
host = "${proxmox_virtual_environment_vm.k3s_control_plane.0.name}.tsh"
user = "root"
private_key = tls_private_key.ssh.private_key_pem
agent = false
# An ssh-agent with your SSH private keys should be running
# Use 'private_key' to set the SSH key otherwise
# Try to complete in at most 15 minutes and wait 5 seconds between retries
timeout = "5m"
retry_delay = "5s"
commands = [
"cat /etc/rancher/k3s/k3s.yaml"
]
triggers = {
always_run = "${timestamp()}"
}
depends_on = [ terraform_data.clean_ssh_known_hosts ]
}
output "kubeconfig" {
# grab this output from terraform with the following command
# terraform output -raw kubeconfig > ~/.kube/config
value = length(ssh_sensitive_resource.grab_kubeconfig) != 0 ? ssh_sensitive_resource.grab_kubeconfig.0.result : 0
sensitive = true
}
# finally write the content of kubeconfig to ~/.kube/config automatically
resource "local_sensitive_file" "local_user_kubeconfig" {
count = length(proxmox_virtual_environment_vm.k3s_control_plane) != 0 ? 1 : 0
content = ssh_sensitive_resource.grab_kubeconfig.0.result
filename = pathexpand("~/.kube/config")
depends_on = [ ssh_sensitive_resource.grab_kubeconfig ]
}
Creemos el control plane con terraform:
[ 2:10PM ] [ toshi@turmalina:~/dev/alberinfra/terraform(master✗) ]
$ terraform apply -var-file="vars.tfvars"
tls_private_key.ssh: Refreshing state... [id=fc8e10ca14b36c8be3389e57006877903259b17f]
proxmox_virtual_environment_file.cloud_config: Refreshing state... [id=terraform_snippets:snippets/cloud-config.yaml]
proxmox_virtual_environment_file.k3s_etcd_cloudinit: Refreshing state... [id=terraform_snippets:snippets/k3s-etcd-cloud-config.yaml]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# local_sensitive_file.local_user_kubeconfig[0] will be created
+ resource "local_sensitive_file" "local_user_kubeconfig" {
+ content = (sensitive value)
+ content_base64sha256 = (known after apply)
+ content_base64sha512 = (known after apply)
+ content_md5 = (known after apply)
+ content_sha1 = (known after apply)
+ content_sha256 = (known after apply)
+ content_sha512 = (known after apply)
+ directory_permission = "0700"
+ file_permission = "0700"
+ filename = "/home/toshi/.kube/config"
+ id = (known after apply)
}
[...]
# proxmox_virtual_environment_vm.k3s_control_plane[0] will be created
+ resource "proxmox_virtual_environment_vm" "k3s_control_plane" {
+ acpi = true
+ bios = "seabios"
+ description = "k3s cluster managed by Terraform"
+ id = (known after apply)
+ ipv4_addresses = (known after apply)
+ ipv6_addresses = (known after apply)
+ keyboard_layout = "en-us"
+ mac_addresses = (known after apply)
+ machine = "q35"
+ migrate = false
+ name = "k3s-control-plane-0"
+ network_interface_names = (known after apply)
+ node_name = "px-03"
+ on_boot = true
+ protection = false
+ reboot = false
+ scsi_hardware = "virtio-scsi-pci"
+ started = true
+ stop_on_destroy = false
+ tablet_device = true
+ tags = [
+ "terraform",
+ "k3s",
+ "control-plane",
]
+ template = false
+ timeout_clone = 1800
+ timeout_create = 1800
+ timeout_migrate = 1800
+ timeout_move_disk = 1800
+ timeout_reboot = 1800
+ timeout_shutdown_vm = 1800
+ timeout_start_vm = 1800
+ timeout_stop_vm = 300
+ vm_id = 5050
+ agent {
+ enabled = true
+ timeout = "15m"
+ trim = false
+ type = "virtio"
}
+ clone {
+ datastore_id = "cluster_drives"
+ full = true
+ node_name = "px-03"
+ retries = 1
+ vm_id = 9666
}
+ cpu {
+ architecture = "x86_64"
+ cores = 2
+ hotplugged = 0
+ limit = 0
+ numa = false
+ sockets = 1
+ type = "x86-64-v2-AES"
+ units = 1024
}
+ initialization {
+ datastore_id = "local-lvm"
+ upgrade = (known after apply)
+ user_data_file_id = (known after apply)
+ ip_config {
+ ipv4 {
+ address = "dhcp"
}
}
}
+ memory {
+ dedicated = 2048
+ floating = 2048
+ keep_hugepages = false
+ shared = 0
}
+ network_device {
+ bridge = "vmbr0"
+ enabled = true
+ firewall = false
+ mac_address = "ee:ee:ee:00:00:10"
+ model = "virtio"
+ mtu = 0
+ queues = 0
+ rate_limit = 0
+ vlan_id = 0
}
+ operating_system {
+ type = "l26"
}
+ vga {
+ memory = 16
+ type = "std"
}
}
# ssh_sensitive_resource.grab_kubeconfig[0] will be created
+ resource "ssh_sensitive_resource" "grab_kubeconfig" {
+ agent = false
+ bastion_port = "22"
+ commands = [
+ "cat /etc/rancher/k3s/k3s.yaml",
]
+ commands_after_file_changes = true
+ host = "k3s-control-plane-0.tsh"
+ id = (known after apply)
+ ignore_no_supported_methods_remain = false
+ port = "22"
+ private_key = (sensitive value)
+ result = (sensitive value)
+ retry_delay = "5s"
+ timeout = "5m"
+ triggers = (known after apply)
+ user = "root"
+ when = "create"
}
# terraform_data.clean_ssh_known_hosts[0] will be created
+ resource "terraform_data" "clean_ssh_known_hosts" {
+ id = (known after apply)
}
Plan: 5 to add, 0 to change, 0 to destroy.
Changes to Outputs:
~ control_plane_hostnames = [
+ "k3s-control-plane-0",
]
~ kubeconfig = (sensitive value)
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yES!
proxmox_virtual_environment_file.k3s_control_plane_cloudinit[0]: Creating...
proxmox_virtual_environment_file.k3s_control_plane_cloudinit[0]: Creation complete after 0s [id=terraform_snippets:snippets/k3s-control-plane-0-cloud-config.yaml]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Creating...
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [10s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [20s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [30s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [40s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [50s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [1m0s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [1m10s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [1m20s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [1m30s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [1m40s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [1m50s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Still creating... [2m0s elapsed]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Creation complete after 2m5s [id=5050]
terraform_data.clean_ssh_known_hosts[0]: Creating...
terraform_data.clean_ssh_known_hosts[0]: Provisioning with 'local-exec'...
terraform_data.clean_ssh_known_hosts[0] (local-exec): Executing: ["/bin/sh" "-c" "ssh-keygen -f \"/home/$USER/.ssh/known_hosts\" -R \"k3s-control-plane-0.tsh\""]
terraform_data.clean_ssh_known_hosts[0] (local-exec): # Host k3s-control-plane-0.tsh found: line 47
terraform_data.clean_ssh_known_hosts[0] (local-exec): /home/toshi/.ssh/known_hosts updated.
terraform_data.clean_ssh_known_hosts[0] (local-exec): Original contents retained as /home/toshi/.ssh/known_hosts.old
terraform_data.clean_ssh_known_hosts[0]: Creation complete after 0s [id=31f50cec-46e2-b9c9-a343-b93ffce76b42]
ssh_sensitive_resource.grab_kubeconfig[0]: Creating...
ssh_sensitive_resource.grab_kubeconfig[0]: Still creating... [10s elapsed]
ssh_sensitive_resource.grab_kubeconfig[0]: Still creating... [20s elapsed]
ssh_sensitive_resource.grab_kubeconfig[0]: Still creating... [30s elapsed]
ssh_sensitive_resource.grab_kubeconfig[0]: Creation complete after 32s [id=7996163503264882213]
local_sensitive_file.local_user_kubeconfig[0]: Creating...
local_sensitive_file.local_user_kubeconfig[0]: Creation complete after 0s [id=4f1a874c917b0ba076bf53abab934f6105f5e266]
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
Outputs:
control_plane_hostnames = [
"k3s-control-plane-0",
]
kubeconfig = <sensitive>
private_key = <sensitive>
Tuqui. :)
Mientras ejecutamos terraform, esta preciosura empieza a ronronear:
 Vista frontal, con línea roja para urgencias conectada a la CCC EPVPN
Vista frontal, con línea roja para urgencias conectada a la CCC EPVPN
 Vista d’cotè
Vista d’cotè
 Switch principal
Switch principal
 Vista dorsal, la máquina inferior corre pfSense y distribuye la internet a todas las partes de la casa
Vista dorsal, la máquina inferior corre pfSense y distribuye la internet a todas las partes de la casa
Muy bueno el rack de madera ¿no?
Heh, bueno. Seguimos.
Hacemos lo mismo, agregando un agente para que el control-plane no se coma toda la carga de lo que vamos a hacer más tarde:
resource "proxmox_virtual_environment_vm" "k3s_agent" {
count = var.k3s_agent_instances
node_name = var.proxmox_main_node_name
vm_id = "507${count.index}"
name = "${var.k3s_hostname_prefix}-agent-${count.index}"
description = "k3s cluster managed by Terraform"
tags = ["terraform", "k3s", "agent"]
started = true
agent {
enabled = true
}
machine = "q35"
cpu {
architecture = "x86_64"
cores = 2
sockets = 1
type = "x86-64-v2-AES"
}
memory {
dedicated = 1024 * 4
floating = 1024 * 4 // set equal to dedicated to enable ballooning
}
// overlay the disk that comes with `packer`
// this settings are the same as configured
// in our ubuntu packer template for proxmox
disk {
interface = "virtio0" # overlay the first disk
datastore_id = var.proxmox_disks_nas_storage_pool
size = 8 # in gigabytes
cache = "writeback"
file_format = "qcow2"
replicate = false
}
// second disk -- this gives the agents more disk space
// than the other VMs
disk {
interface = "virtio1" # attach it as a second disk
datastore_id = "cluster_drives"
size = 200 # in gigabytes
cache = "writeback"
file_format = "qcow2"
replicate = false
}
initialization {
ip_config {
ipv4 {
address = "dhcp"
}
}
user_data_file_id = element(proxmox_virtual_environment_file.k3s_agent_cloudinit.*.id, count.index)
}
network_device {
bridge = "vmbr0"
mac_address = "ee:ee:ee:00:00:5${count.index}"
}
operating_system {
type = "l26"
}
vga {
memory = 16
type = "std"
}
//serial_device {}
clone {
vm_id = 9666
node_name = var.proxmox_main_node_name
datastore_id = var.proxmox_disks_nas_storage_pool
}
depends_on = [ proxmox_virtual_environment_vm.k3s_control_plane ]
}
[ 2:18PM ] [ toshi@turmalina:~/dev/alberinfra/terraform(master✗) ]
$ terraform apply -var-file="vars.tfvars"
tls_private_key.ssh: Refreshing state... [id=fc8e10ca14b36c8be3389e57006877903259b17f]
proxmox_virtual_environment_file.cloud_config: Refreshing state... [id=terraform_snippets:snippets/cloud-config.yaml]
proxmox_virtual_environment_file.k3s_etcd_cloudinit: Refreshing state... [id=terraform_snippets:snippets/k3s-etcd-cloud-config.yaml]
proxmox_virtual_environment_file.k3s_control_plane_cloudinit[0]: Refreshing state... [id=terraform_snippets:snippets/k3s-control-plane-0-cloud-config.yaml]
proxmox_virtual_environment_vm.k3s_control_plane[0]: Refreshing state... [id=5050]
terraform_data.clean_ssh_known_hosts[0]: Refreshing state... [id=31f50cec-46e2-b9c9-a343-b93ffce76b42]
ssh_sensitive_resource.grab_kubeconfig[0]: Refreshing state... [id=7996163503264882213]
local_sensitive_file.local_user_kubeconfig[0]: Refreshing state... [id=4f1a874c917b0ba076bf53abab934f6105f5e266]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
-/+ destroy and then create replacement
Terraform will perform the following actions:
[ ... ]
# proxmox_virtual_environment_vm.k3s_agent[0] will be created
+ resource "proxmox_virtual_environment_vm" "k3s_agent" {
+ acpi = true
+ bios = "seabios"
+ description = "k3s cluster managed by Terraform"
+ id = (known after apply)
+ ipv4_addresses = (known after apply)
+ ipv6_addresses = (known after apply)
+ keyboard_layout = "en-us"
+ mac_addresses = (known after apply)
+ machine = "q35"
+ migrate = false
+ name = "k3s-agent-0"
+ network_interface_names = (known after apply)
+ node_name = "px-03"
+ on_boot = true
+ protection = false
+ reboot = false
+ scsi_hardware = "virtio-scsi-pci"
+ started = true
+ stop_on_destroy = false
+ tablet_device = true
+ tags = [
+ "terraform",
+ "k3s",
+ "agent",
]
+ template = false
+ timeout_clone = 1800
+ timeout_create = 1800
+ timeout_migrate = 1800
+ timeout_move_disk = 1800
+ timeout_reboot = 1800
+ timeout_shutdown_vm = 1800
+ timeout_start_vm = 1800
+ timeout_stop_vm = 300
+ vm_id = 5070
+ agent {
+ enabled = true
+ timeout = "15m"
+ trim = false
+ type = "virtio"
}
+ clone {
+ datastore_id = "cluster_drives"
+ full = true
+ node_name = "px-03"
+ retries = 1
+ vm_id = 9666
}
+ cpu {
+ architecture = "x86_64"
+ cores = 2
+ hotplugged = 0
+ limit = 0
+ numa = false
+ sockets = 1
+ type = "x86-64-v2-AES"
+ units = 1024
}
+ disk {
+ aio = "io_uring"
+ backup = true
+ cache = "writeback"
+ datastore_id = "cluster_drives"
+ discard = "ignore"
+ file_format = "qcow2"
+ interface = "virtio0"
+ iothread = false
+ path_in_datastore = (known after apply)
+ replicate = false
+ size = 8
+ ssd = false
}
+ disk {
+ aio = "io_uring"
+ backup = true
+ cache = "writeback"
+ datastore_id = "cluster_drives"
+ discard = "ignore"
+ file_format = "qcow2"
+ interface = "virtio1"
+ iothread = false
+ path_in_datastore = (known after apply)
+ replicate = false
+ size = 200
+ ssd = false
}
+ initialization {
+ datastore_id = "local-lvm"
+ upgrade = (known after apply)
+ user_data_file_id = (known after apply)
+ ip_config {
+ ipv4 {
+ address = "dhcp"
}
}
}
+ memory {
+ dedicated = 4096
+ floating = 4096
+ keep_hugepages = false
+ shared = 0
}
+ network_device {
+ bridge = "vmbr0"
+ enabled = true
+ firewall = false
+ mac_address = "ee:ee:ee:00:00:50"
+ model = "virtio"
+ mtu = 0
+ queues = 0
+ rate_limit = 0
+ vlan_id = 0
}
+ operating_system {
+ type = "l26"
}
+ vga {
+ memory = 16
+ type = "std"
}
}
# ssh_sensitive_resource.grab_kubeconfig[0] must be replaced
-/+ resource "ssh_sensitive_resource" "grab_kubeconfig" {
~ id = "7996163503264882213" -> (known after apply)
~ result = (sensitive value)
~ triggers = { # forces replacement
- "always_run" = "2024-12-17T13:14:11Z"
} -> (known after apply) # forces replacement
# (12 unchanged attributes hidden)
}
Plan: 4 to add, 0 to change, 2 to destroy.
Changes to Outputs:
~ kubeconfig = (sensitive value)
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
local_sensitive_file.local_user_kubeconfig[0]: Destroying... [id=4f1a874c917b0ba076bf53abab934f6105f5e266]
local_sensitive_file.local_user_kubeconfig[0]: Destruction complete after 0s
proxmox_virtual_environment_file.k3s_agent_cloudinit[0]: Creating...
ssh_sensitive_resource.grab_kubeconfig[0]: Destroying... [id=7996163503264882213]
ssh_sensitive_resource.grab_kubeconfig[0]: Destruction complete after 0s
ssh_sensitive_resource.grab_kubeconfig[0]: Creating...
proxmox_virtual_environment_file.k3s_agent_cloudinit[0]: Creation complete after 0s [id=terraform_snippets:snippets/k3s-agent-0-cloud-config.yaml]
proxmox_virtual_environment_vm.k3s_agent[0]: Creating...
ssh_sensitive_resource.grab_kubeconfig[0]: Creation complete after 0s [id=7130346671968112612]
local_sensitive_file.local_user_kubeconfig[0]: Creating...
local_sensitive_file.local_user_kubeconfig[0]: Creation complete after 0s [id=4f1a874c917b0ba076bf53abab934f6105f5e266]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [10s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [20s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [30s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [40s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [50s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [1m0s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [1m10s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [1m20s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [1m30s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [1m40s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [1m50s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [2m0s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Still creating... [2m10s elapsed]
proxmox_virtual_environment_vm.k3s_agent[0]: Creation complete after 2m13s [id=5070]
Apply complete! Resources: 4 added, 0 changed, 2 destroyed.
Outputs:
control_plane_hostnames = [
"k3s-control-plane-0",
]
kubeconfig = <sensitive>
private_key = <sensitive>
Próximos Pasos
Una vez que ya tenemos andando nuestro cluster Kubernetes,
podemos hacer con él lo que queramos.
Lo que hice en mi caso fue instalar GitLab y FluxCD
para aplicar el framework GitOps y tener un Single Source of Truth.
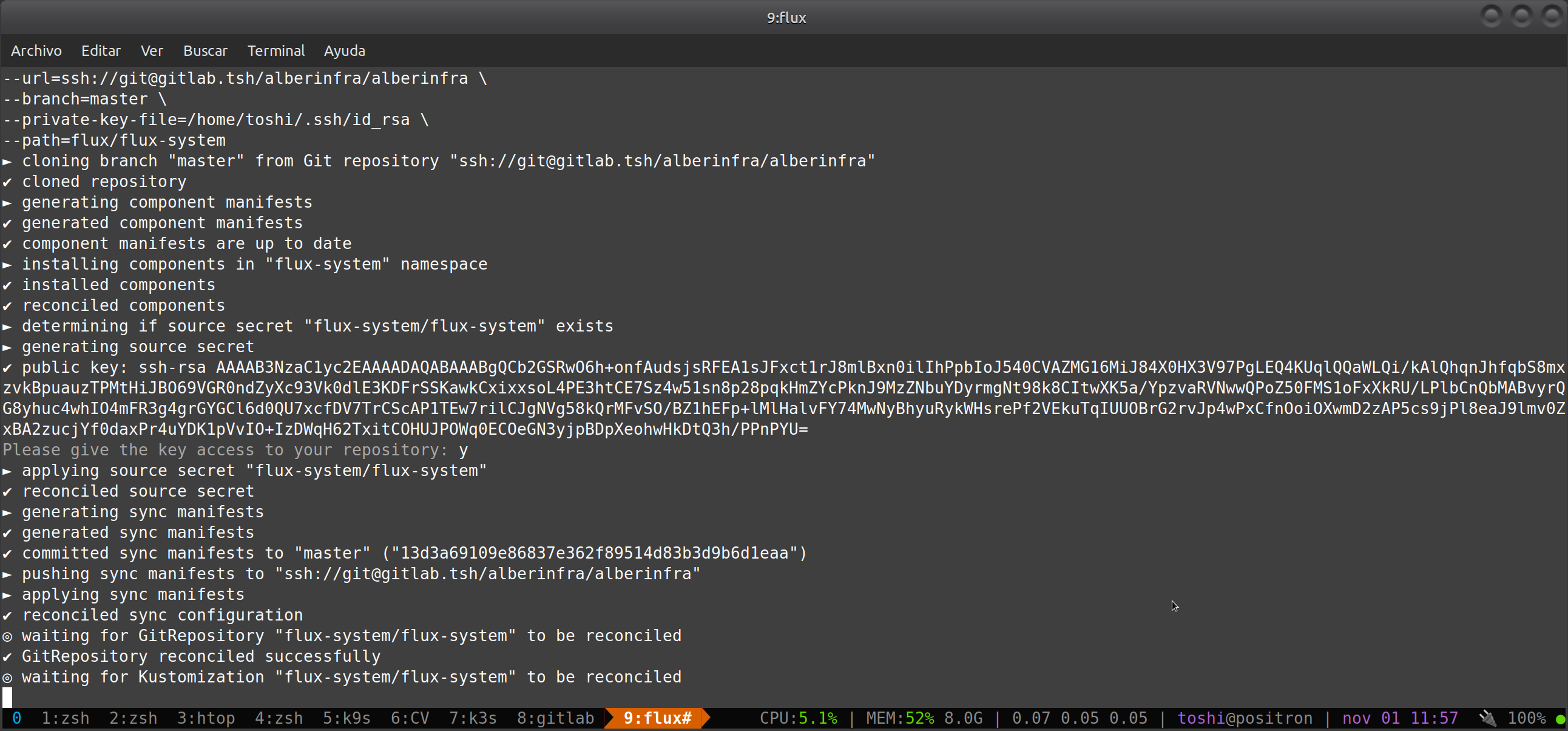 Flux Bootstrap Reconcile
Flux Bootstrap Reconcile
En mi caso, toda la infraestructura, kubernetes y las
aplicaciones y containers que corren sobre el cluster,
estan todas definidas en un único repositorio que Flux
está mirando constantemente cuando hay nuevos pushes en
el repositorio donde están todas las definiciones.
Cualquier cambio que se haga en mi repo, modifica alguna parte
del cluster.
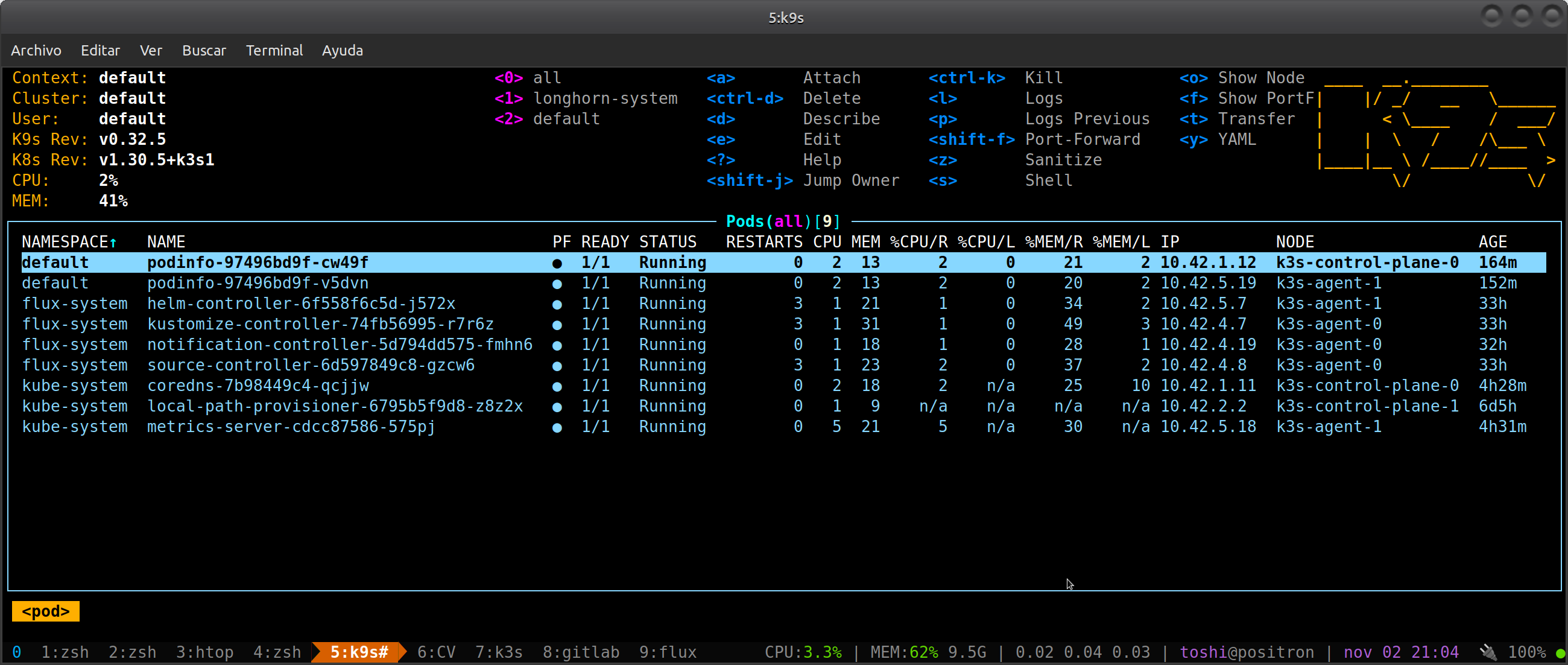 Flux y podinfo corriendo en mi cluster k8s
Flux y podinfo corriendo en mi cluster k8s
Y en caso de querer mandar todo a la mierda y volar el cluster, solo basta con un dulce y tierno terraform destroy :D
Si llegaste hasta acá y te sirvió: ¡Salud!